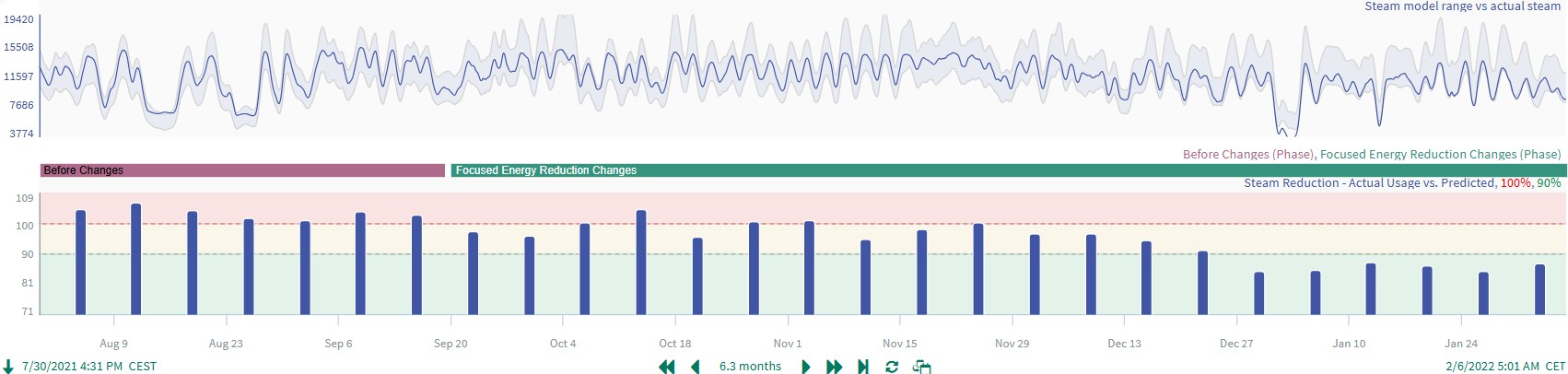
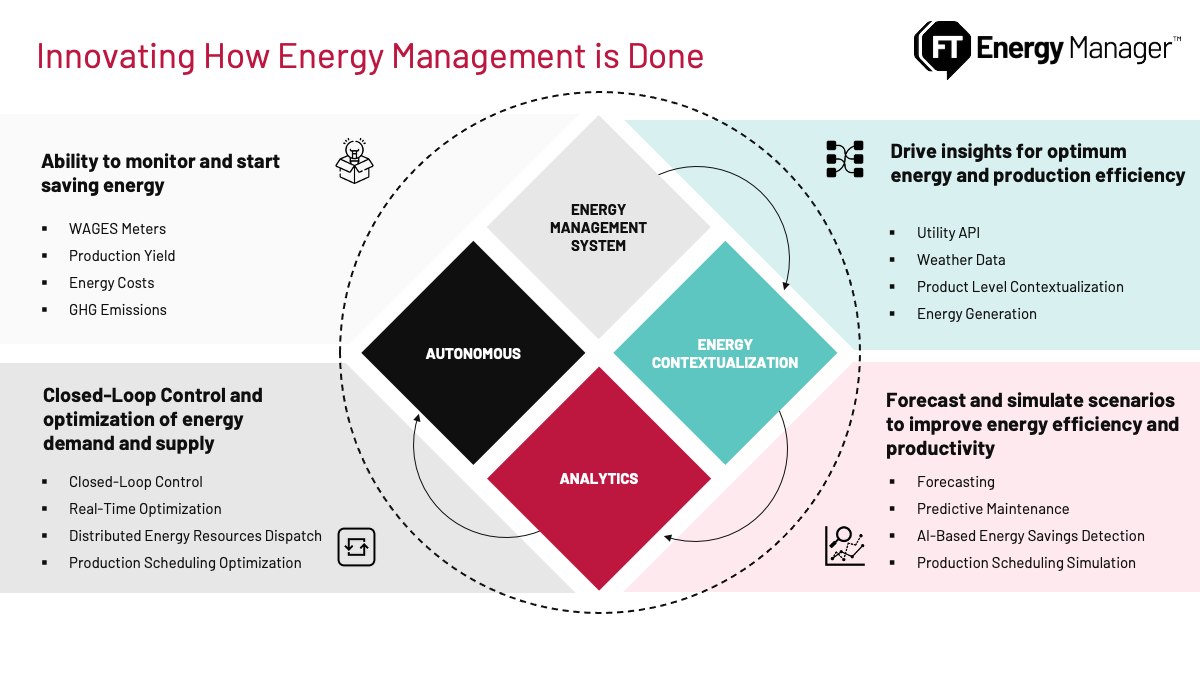
Energy Efficiency and Management How to apply self-service analytics to monitor plant energy efficiency