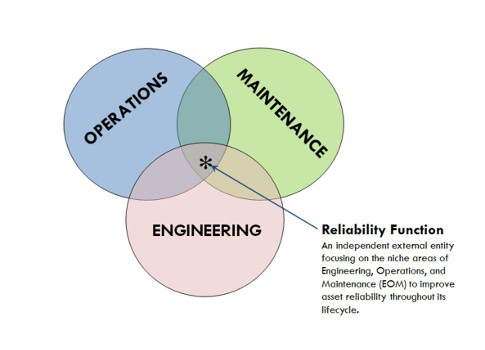
It is about time to disconnect the reliability function from maintenance and make it an autonomous external entity, focusing on asset reliability at every level in the Asset Lifecycle Management (ALM).
It is a resounding fact that the need for advancement in the plant maintenance field gave birth to the function of reliability. But isn’t it about time we disconnect this child from its umbilical cord and allow the reliability function to stand on its own feet, independent from maintenance? Shouldn’t we now let this child unleash the true potential it has to offer to the industry by being an autonomous external entity, focusing on asset reliability at every level in the Asset Lifecycle Management (ALM)?
There is no doubt that early reliability techniques were evolved to strategically handle plant maintenance. Predicting failures in advance and allocating sufficient resources helped the industry in mitigating the impact of unexpected failures and unplanned outages. The early techniques also prevented maintenance folks from patching up the failures and demanded detailed root-cause studies so problems leading to failures are fixed once and for all. But after many years, the function of reliability is still so tightly married to maintenance that it is often perceived to be the only combination that can unlock all challenges related to an asset. But can maintenance alone handle all aspects of reliability throughout the lifecycle of an asset? What if the asset has inherent design flaws or inadequate commissioning procedures? What if it is being operated outside of its operating parameters? Such issues are related to Engineering and Operations, which are outside of the Maintenance scope.
The primary function of maintenance — that takes precedence over all other roles — is “firefighting”. When equipment breaks down, the maintenance team is expected to return it to service immediately so the production can be restored. The function of reliability has nothing to do with this firefighting approach. Thinking of reliability as an improved maintenance practice does not do justice to this function and limits our imagination to what it can truly deliver. It is very common in the industry to interchange the term maintenance engineer with reliability engineer without much thought. The majority of reliability engineers are still perceived as “smart” maintenance engineers or engineers who deal with the maintenance related issues of high-dollar value assets such as compressors and large rotating equipment. It almost seems inconceivable, even to many industry professionals, that a reliability engineer has a much broader goal and is better off being an independent entity overseeing the Engineering, Operations and Maintenance (EOM) to embed reliability at every level. Just as the Safety Group is effective in incorporating its policies and programs within EOM’s routine business, the notion of having an independent reliability group doing the same for reliability programs and initiatives should not be alien at all.
If you want a reliable car, you must first ensure that the car is built to be reliable. You then make sure it is operated as it was intended to be during the design. Last, you focus on the maintenance and take measures to do it right and on time. All three, the designer, the operator and the maintainer must adhere to reliability to have a reliable car. The same philosophy applies to the plant assets — maintenance alone should not be deemed responsible for their reliability. Just like a car, equipment can only be truly reliable if the engineering team ensures reliability during the procurement and commissioning phases, the operations crew operates it as per the standard operating procedures without exceeding the operating envelope, and the maintenance folks exercise due diligence in maintaining reliability with quality workmanship.
The single entity that can ensure the collaboration within these three disciplines and oversee reliability through the entire lifecycle of an asset is the function of a reliability engineer. The reliability engineer does not necessarily have to be a mechanical engineer. This role can also be taken by an Electrical or I&C engineer having sufficient industry experience and sound knowledge of reliability engineering tools and techniques. However, for a reliability program to be effective in a plant, one must realize that this is not a one-man show. It is recommended that an independent group be established to launch a comprehensive reliability program. That group must consist of several reliability engineers who are preferably a mix of mechanical, electrical and I&C engineers, CMMS experts, senior technicians, and at least one representative each from EOM. This group must report to the entity having authority over EOM. It is important since reliability mandates changes and enhancements in the traditional style of work and, as commonly known, the change is always resisted and often counterattacked.
The reliability group must focus on strategic programs and the management must realize that such programs require long-term commitment and support to be able to produce expected results. The list below identifies some of the labor-intensive programs and analytical activities that can be undertaken by the group. This is by no means a comprehensive list, but each organization can customize it with additional programs based on its size and resources. Several programs listed here are considered to be “living” and require a twofold approach to be fruitful. First, develop a detailed scope of work covering the feasibility and implementation requirements for management support and approval. Second, execute the program and be on the lookout for areas of improvement while constantly bridging any gaps identified.
Some recommended strategic programs for the reliability group include:
- RCM: Reliability Centered Maintenance (RCM) program covering seven questions of RCM methodology.
- PM: Develop preventive maintenance (PM) procedures and optimize utilizing failure modes.
- PdM: Implement predictive maintenance technology and develop continuous monitoring program. For example; online/offline vibration monitors, ultrasound measurement devices, thermographs, oil condition monitoring, and smart instrumentation online diagnostics.
- ODR: Operator Driven Reliability (ODR) program focusing on the operations role to enhance asset reliability. This may include detailed operators checklists for visual/audio/smell/feel tests, review and enhancement of standard operating procedures (SOP), accurate integrity operating window (IOW) for all equipment, simple handheld devices to collect data for offline predictive maintenance, and minor maintenance tasks, like tightening up loose bolts with basic tools.
- FMEA/FMECA: Failure modes, effects, and criticality analysis.
- RCA/RCFA: Root cause failure analysis covering effective failure reporting and close tracking of recommendations until fully implemented.
- SJP: Develop standard job plans for better planning and scheduling of work orders with accurate resource handling.
- PHA: Participation in process hazard analysis like HAZOP.
- LOPA: Layer of protection analysis or other qualitative analyses for safety instrumented systems.
- SIS: Safety instrumented system lifecycle management covering all phases from cradle to grave and compliance with industry and company standards. SIF (safety instrumented function) performance like Actual Demand Rate, Detected Failure Rates, Proof Test Compliance, and Diagnostics etc. should also be part of this program.
- Functional testing procedures and relevant documentation for non-SIS related equipment.
- Initiation and tracking of a lessons learned database for reliability.
- Capital project packages review with reliability enhancement recommendations.
- Bad actors identification, tracking and replacement program.
- Advanced reliability analyses including but not limited to Weibull analysis, Markov modeling, Lean/Six Sigma study, and RAM (reliability, availability, and maintainability).
- Obsolete equipment tracking and systematic replacement program.
- Ad-hoc site visits to witness the operations and maintenance work with the intention of issuing recommendations for identified gaps.
- Random checks for CMMS/SAP data entry and quality.
- SPF: Single point of failure identification and enhancement.
- DFR: Design for reliability program and related studies.
- Reliability Performance Metrics: Develop, track, and enhance leading/lagging KPIs. For example: MTBF (mean time between failures), MTTR (mean time to repair), OEE (overall equipment efficiency), Equipment availability, and Equipment PFDs (probability of failure on demand).
In conclusion, the function of reliability has evolved immensely over the years. Allowing reliability to operate independently, focusing on its core strengths without getting consumed by daily firefighting work from maintenance, will take this function to another dimension of ingenuity. Empowering the reliability group to have jurisdiction over engineering, operations, and maintenance (EOM), will ease and expedite the part of change-management while shorten the implementation period through improved collaboration. This is essential since many reliability initiatives fail during execution phase when management does not see results for an extended period and loses interest.
When placed correctly in an organization, along with the necessary expertise, resources, and authority, the function of reliability will demonstrate the true potential it has in improving asset reliability during its lifecycle, and in achieving a robust reliability culture throughout the facility.
Disclaimer: The author’s views do not necessarily reflect the views of his employers, colleagues or any professional societies he is affiliated with.
References: The hedgehog concept of 3-Circles is depicted from Jim Collins book, "Good to Great"
– Obaidullah A. Syed, CFSP, CMRP, P.E. has nearly 20 years of experience in the controls and automation industry, primarily serving oil and gas companies. His experience comes from a blend of project engineering, functional safety and reliability engineering work. Since 2007, he has worked in Saudi Arabia. Edited by Joy Chang, digital project manager, Plant Engineering, [email protected].