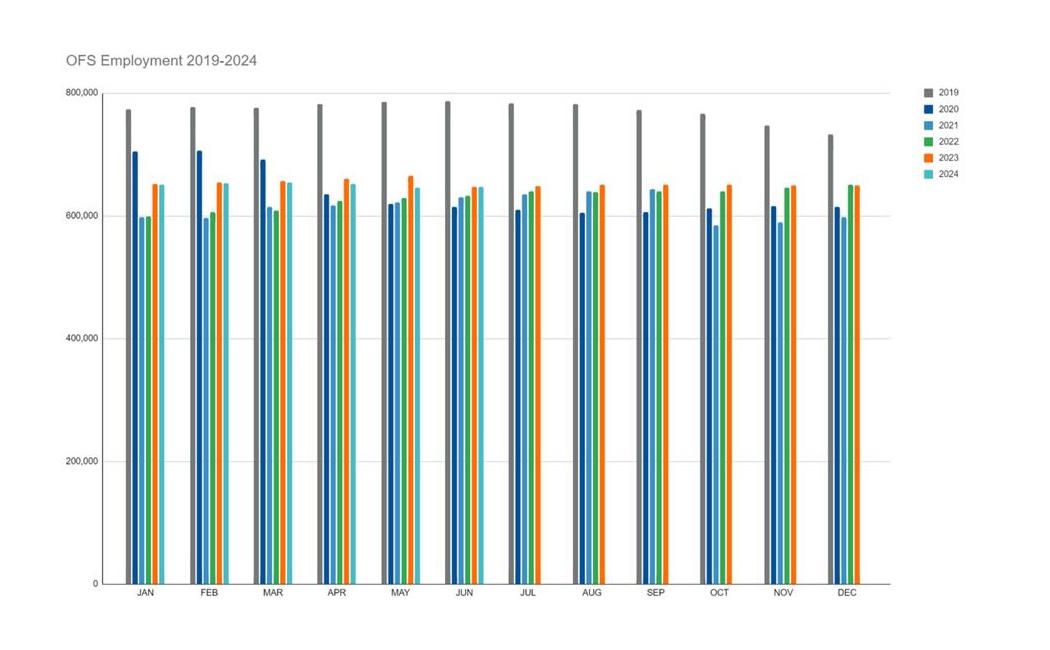
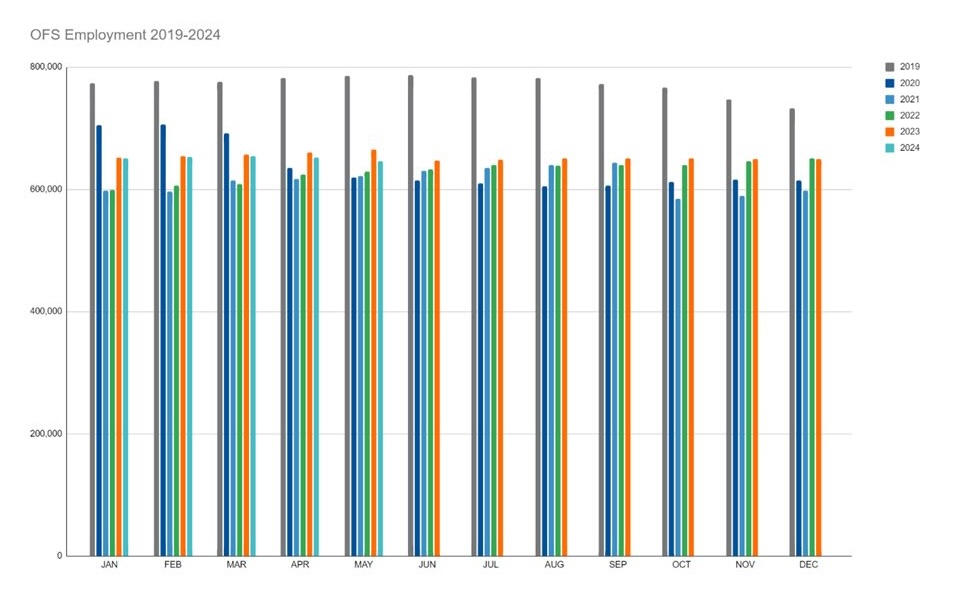
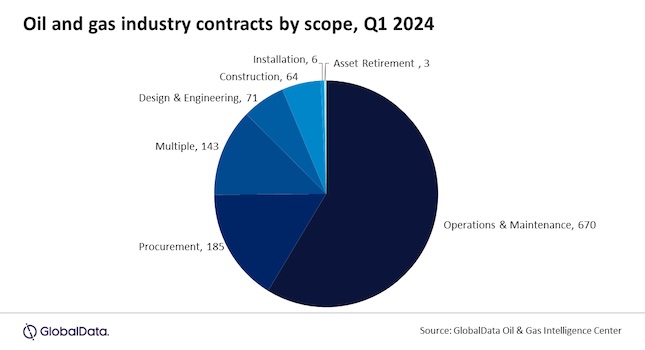
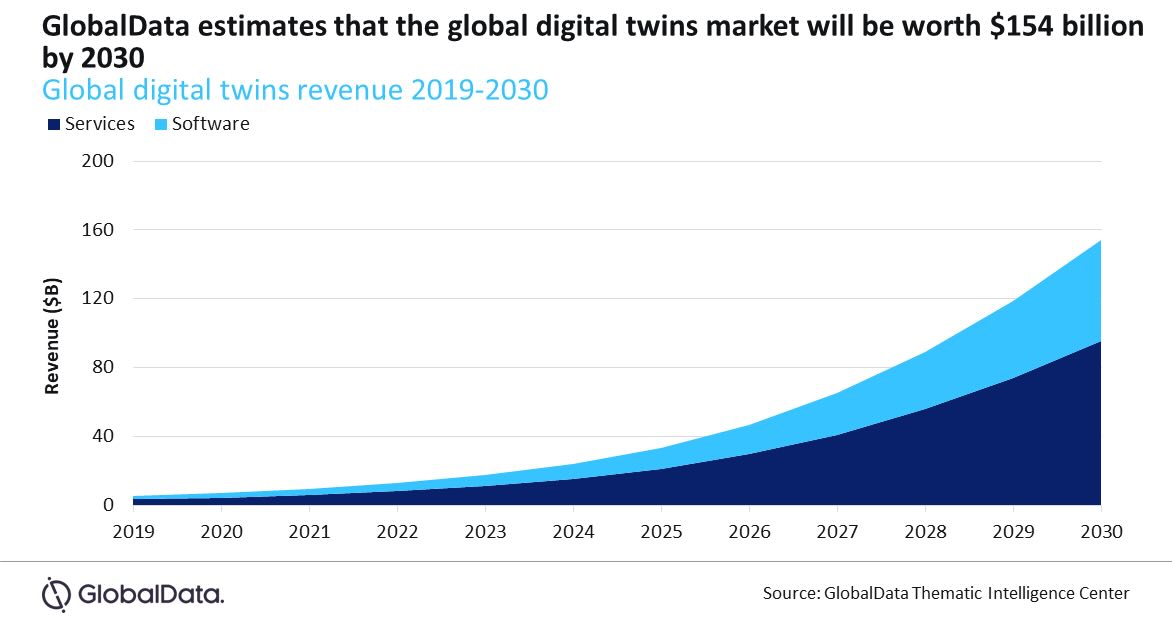
Case study example illustrates challenges and opportunities
Digitalization of production and process operations has the potential to boost profit margins by three to five percentage points — but only if people can make the new technologies work at scale. According to a McKinsey survey, nearly 30% of executives reported active pilot projects, while 71% expected significant increase in AI investment. However, the survey found that progress remained slow.
Most companies don’t have infrastructure for sourcing data and scaling artificial intelligence (AI) initiatives. Experts often address AI transformation at large enterprises. However, the focus has been on vision, strategy, people and culture. While important, these overlook other, multidimensional, factors necessary to succeed at scale.
Successful at scale
Working with some of the largest oil & gas and other industrial companies, we at Falkonry have observed that “transformation doesn’t happen from the inside out — it grows on you from the outside in.” Transforming upstream and downstream operations from reactive to predictive processes, where quality, equipment and process-line issues can be prevented before they occur, is the goal for many of these companies.
If you are embarking upon a digital transformation initiative — or if you are already in the process of implementing one — it’s time to step back and look at lessons learned from leaders in this space. From these lessons, here are five best practices (See figure 1) to guide transformation.
Best practice 1: Mass-adoptable technology
Without mass-adoptable technology, there would be no transformation. Mass-adoptable AI technology doesn’t imply simple core tech, but technology where complexity is minimized or hidden from users. Using the technology shouldn’t require data scientists, or historical and labeled data. Such features — which make the technology easy to use, repeatable, and able to deliver ROI in a shorter time — are what drive its adoption.
Best practice 2: Ardent advocates
Most organizations with critical operations are risk averse and are more comfortable making incremental improvements. Transformations require executive champions who are ardent advocates and furnish the necessary mandate and resources to reduce risk for engineering and operations teams. Of the reasons cited as causes of failure in enterprise transformation, basic challenges in human and team behavior top the list. Strong advocates ensure transformations that matter succeed despite these challenges.
Best practice 3: Buy-in
Enterprise buy-in occurs when the results are genuinely insightful and valuable. Stakeholders see that transformation advances their organization’s interests and share in the ownership of the transformation. Early buy-in greatly smooths deployment and measurable results.
Best practice 4: Accountability
Accountability cannot be spared in organizations and being brutally honest about value creation is essential to end up on the right side of the transformation. These accountability efforts can make AI or transformation teams uncomfortable, but it’s important to demand the most return upfront, even within the first 90 days.
Best practice 5: Agile development
While AI grows exponentially more valuable over time, it does not have to take forever. Two years should suffice and both sides should agree on phase exit gates at meaningful intervals. Successful case studies indicate the right exit moments are at 90 days (for proof of concept) and one year (for pilot to production) from the start.
Upstream case study
To highlight the effectiveness of subscribing to the best practices outlined above, let’s look at how they’ve been applied in the oil & gas industry. In offshore oil & gas, rotating machinery such as compressors, pumps and turbines are mission-critical equipment. In this case study, upstream production incorporates floating production storage and offloading (FPSO) vessels, floating liquid natural gas (FLNG) tankers, and floating storage & regasification units (FSRU). The common vulnerability was compressors, which are critical to operations, often single-threaded and periodically fail.
The company experienced unanticipated FPSO and FSRU compressor failures that caused complete or partial loss of production. Repair parts and crews were mobilized to these often-remote operating units. On average, the company estimated that unscheduled downtime resulted in $300,000 of lost production per incident. In addition, installation cost to replace a failed unit was significant when added up across operations.
The company adhered to best practices to ensure digital transformation efforts solved these problems:
- Mass adoptable technology: The team conducted thorough market research and assessment of available predictive analytic solutions. Most predictive maintenance approaches did not leverage operations telemetry and tended to be less robust. The customer chose Falkonry based on the following criteria:
- Ease of use of the software by their operations engineers
- Short time to results based on automated discovery of multivariate patterns within their operational data
- Extensibility to address many use cases and operations problems
- Ease of integration with a data architecture to quickly deploy and operationalize the solution in their environment.
- Ardent advocates: The company established a digital transformation initiative led by the office of the CIO to identify and implement solutions across its operations. FPSO and LNG fleet operations generated a lot of data and the CIO needed a solution that could scale across multiple use cases and asset types. A team was established with members from operations, engineering and IT.
- Buy-in: The FPSO was an early proof-of-concept success. Using the Falkonry LRS software, the engineering team predicted dry seal degradation in the compressor six weeks before the internal operations teams suspected issues. Stakeholders were educated on the benefits and bought into the idea of using machine learning technology. Following the early success, the company is expanding use to onshore operations and identifying other applications for predictive analytics.
- Accountability: The company required data remain within its environment and process engineers retain full control over the data, models and findings. Also ensured was easy integration within its existing data infrastructure and leveraged operational databases that worked within or without enterprise asset management systems.
- Agile development: The customer success team trained the company’s engineers on how to create predictive models themselves. Engineers rapidly created models to discover patterns in time-series data, enabling identification of precursor events to the compressor failures and generation of automated alerts. The three-month proof of concept was then followed by a 12-month production subscription.
Predictive operations results
The company quickly moved from proof-of-concept to full production deployment of predictive operations across multiple compressors and vessels, resulting in significant operational improvement and maintenance costs savings. The deployment enabled them to predict compressor seal failures six weeks earlier than internal operations teams suspected issues.
The total benefit generated from the initial pilot of just two FPSOs was estimated to be $580,000, with the primary benefit being downtime reduction. Additional benefits included reduction in installation cost and increased compressor life.
As highlighted in the above case study, applying machine learning technology in the oil & gas industries can successfully detect, predict, and explain conditions preceding equipment failures, resulting in reduced unexpected downtimes and savings of millions of dollars annually. The benefits of this type of digital transformation are far-reaching but are only achieved if companies make the new technologies work at scale. To do this, they need to consider all the multidimensional factors necessary to succeed at scale and should follow these five best practices: mass adoptable technology, ardent advocates, buy-in, accountability, and agile development.